「CODE COMPLETE」を読んだ感想を書きたい
会社の先輩から勧められて借りてきた。上巻から読んでる。

コンストラクション
この本ではソフトウェアづくりのことをコンストラクションと呼んでる。コンストラクションの範囲のことは語るけどその外のことはこの本の範疇外やでということらしい。コンストラクションの範囲は、ひどいソフトウェア開発だろうがうまいソフトウェア開発だろうが絶対通るような、作る工程のことを指してるっぽい。設計とかは入るけど、顧客折衝とかは入らない感じっぽい。
リーダブルコードだと基本的にコーディングのことばかりだけど、この本はもう少し広い範囲を対象にしてそうというのがわかる。
第5章
第5章は設計の話。設計っていうのはヒューリスティック(発見的)なものであり、決定論的なものじゃないということが書かれている。正解があって、一発で、はいこれねと正解が出せるものではなさそうなのがわかる。
code complete上巻五章読んでる。設計いちから考えるの難しすぎるので、なるべくデザインパターンやフレームワークやら標準的なやり方を理解した上でそれに頼っていかないとおれおれ設計くそコード野郎になってしまうので大変という感想を持った
— gaaamii (@gaaamii) 2019年6月29日
第6章
具体的な話になってきた。ADT(Abstract Data Types)の話。 プログラムのデータ型というとまずstringとかintとかそういうプリミティブなものがあるけど、それをそのまま使うんじゃなくて、現実世界のものを抽象化して表現すると良いぞ、みたいな話。読み進めながら、なるほどオブジェクト指向のクラスの話かと思ったけど、それよりも土台の話らしい。
ADTはクラスの概念の土台となる。クラスをサポートするプログラミング言語では、ADTをそれぞれ専用のクラスとして実装することができる。通常、クラスには他にも継承やポリモーフィズムという概念がある。クラスは「ADT + 継承およびポリモーフィズム」として考えることもできる。
第7章
ルーチンの話。関数(値を返すルーチン)とプロシージャ(値を返さないルーチン)の使い分けなど。C++のマクロの話はあんま関係ないな〜と思って読み飛ばしてしまった。
自分は普段ここで書かれているルーチンの種類を特に区別せず全部関数って呼んでたのだけど、値を返すかどうかによってそうやって言い分けるものなんだ〜というのを学んだりした。
第8章
防御的プログラミングの話。garbage in garbage out (ゴミを入れてゴミを出す)ではだめで、エラーメッセージを出したり、そもそもゴミを入れさせないようにしたりと、ゴミに対処するべきという話。
8.3.1 では堅牢性と正当性という言葉が出てくる。
正当性とは、不正確な結果を決して返さないことを意味する。不正確な結果を返すくらいなら、何も返さない方がましである。堅牢性とは、ソフトウェアの実行を継続できるように手を尽くすことである。
どんなアプリケーションのどんな機能かによって、正当性を優先するか堅牢性を優先するかが変わってくる。正当性を優先すれば、誤ったものがきたときにエラーメッセージを出して処理を中断とかにするだろうし、堅牢性を重視するなら、そうはせずに近い値やデフォルト値みたいなものを変わりに入れて処理を続行したりする。
また、8.4では例外についても触れられている。安易に例外使わないようにしたほうがいいよというスタンスで、こんなことが書かれている。
例外は、予想外の状況に対処する強力な手段と、コードの複雑さの増大とのトレードオフを表す。たとえば、あるルーチンを呼び出すためには、呼び出し元のコードはどこでどの例外がスローされるのかを知らなければならない。したがって、例外はカプセル化を弱め、これによりコードの複雑さが増し、「ソフトウェアの鉄則:複雑さへの対応」にマイナスに働く。
第9章
擬似コードによるプログラミングの話。
第10章
変数の話。なるべく宣言した近くで使おうねという話など。
第11章
第11章は変数の名前の話。その変数が持つ意味を考えて、あとで読んだときに推理しないでもぱっとわかる変数名つけようねという話。
第12章
第12章は基本的なデータ型。浮動小数点数の話とか。
書き途中です。
Ruby製のウェブサーバライブラリWebrickのソースコードを読む
そういや一年前、「ウェブサーバーのこと知りたい -> Rack読もう。」となって挫折した。少しずつ暖かくなって意識が高まってきたし、今やっている仕事がずいぶんと(すくなくともRailsアプリ書くのと比較すると)低レイヤーなところなので、良い感じの相乗効果を狙って今のうちにサーバーについて理解を深めておきたい。そういうわけで、今春はWebrick読もう。
読みかた
今度は挫折したくない。以下の手法に従って読む。
また、Cのソースにも触れることになると思うので以下も参考にする。
使うもの
動的解析
基本的に解析は動的解析から始めるのがよい。 静的解析とは、多かれ少なかれ、プログラムの動作を予想することである。 対して動的解析で見るのは事実である。 まず事実を見ておいたほうが方向付けがしやすいし、間違いも減る。 最適化する前にプロファイルを取れ、というのと似ているだろうか。 事件解決はまず現場から、というのでもよい。
とのこと。まずは動かす。
サーバー起動
ruby -rwebrick -e 'WEBrick::HTTPServer.new(:DocumentRoot => "./", :Port => 8000).start'
なお、これは以下と同等(r オプション使うの初めてだ)。
ruby -e 'require "webrick";WEBrick::HTTPServer.new(:DocumentRoot => "./", :Port => 8000).start '
[2016-03-26 14:03:45] INFO WEBrick 1.3.1 [2016-03-26 14:03:45] INFO ruby 2.2.3 (2015-08-18) [x86_64-darwin14] [2016-03-26 14:03:45] INFO WEBrick::HTTPServer#start: pid=4563 port=8000
リクエストを投げる
クライアントとして、別のシェルを開いて以下を実行する。
curl localhost:8000
(クライアント側)
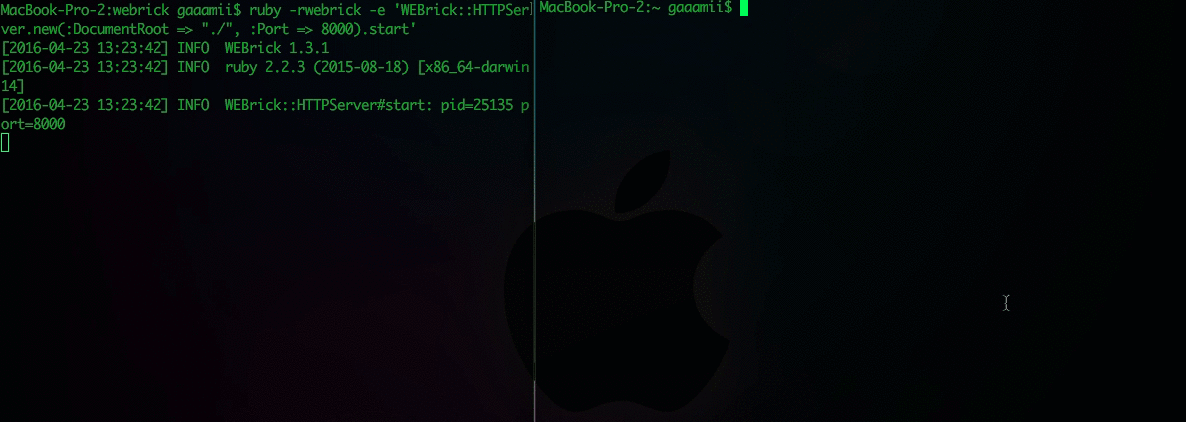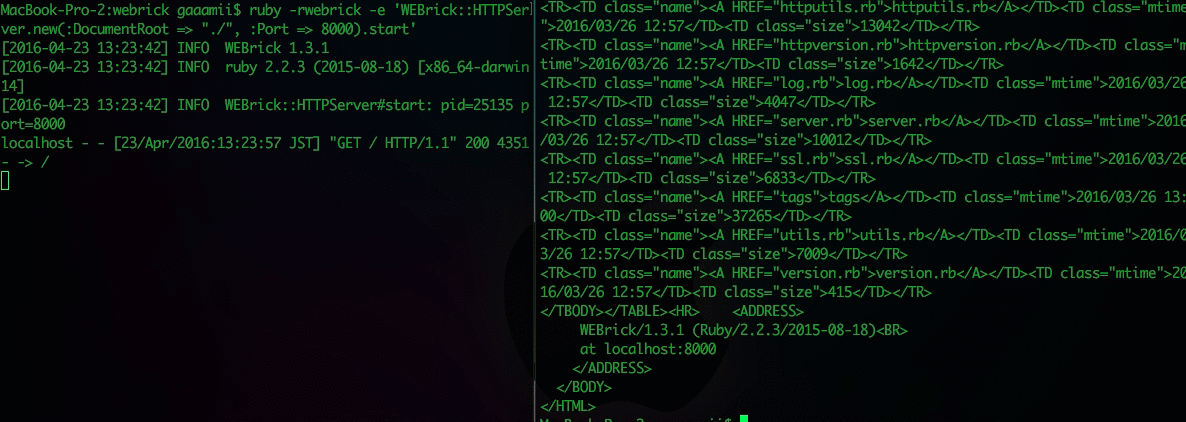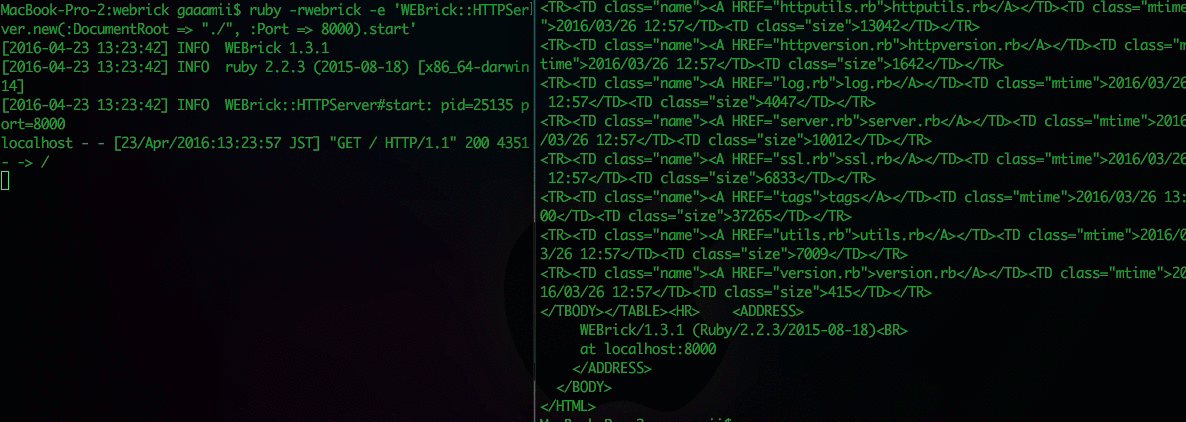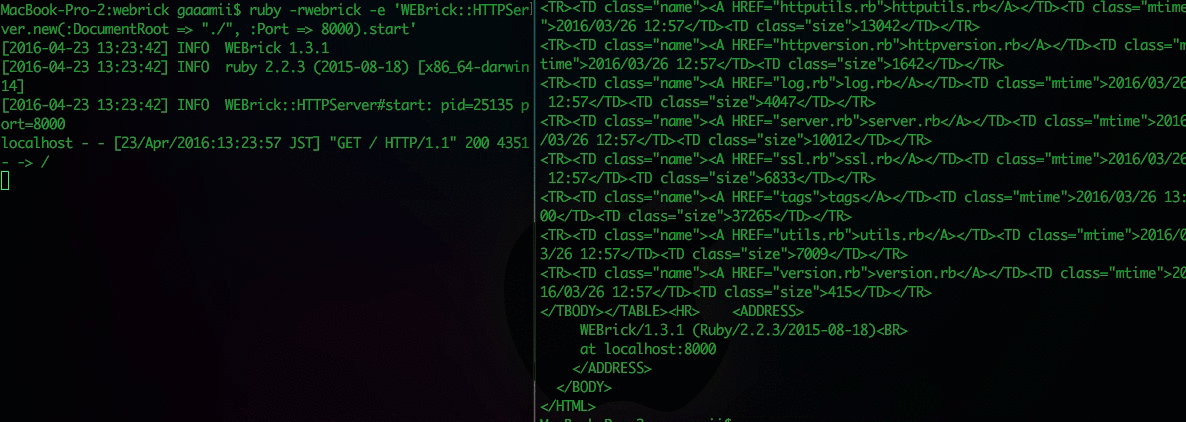
$ curl localhost:8000
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
<HTML>
<HEAD>
<TITLE>Index of /</TITLE>
<style type="text/css">
...(以下略)
(サーバー側)
localhost - - [26/Mar/2016:14:04:04 JST] "GET / HTTP/1.1" 200 4076 - -
クライアントからHTTPリクエストを投げたらちゃんとハイパーテキストを返してくれたので、ウェブサーバーとして機能したと言える。サーバー側のログには時刻やHTTPメソッド・プロトコルのバージョン・ステータスなどが出されている。
静的解析
前準備
さすがにGithubのウェブサイト上でファイルを一つ一つブラウジングして理解できる気がしないので、「ソースコード完全解説ガイド」に従っていくつかの前準備を行う。
ドキュメントを読む
今回は http://docs.ruby-lang.org の説明を参照する。
汎用HTTPサーバーフレームワークです。HTTPサーバが簡単に作れます。
WEBrick はサーブレットによって機能します。サーブレットとは サーバの機能をオブジェクト化したものです。 ファイルを読み込んで返す・forkしてスクリプトを実行する・テンプレートを適用する など、「サーバが行なっている様々なこと」を抽象化しオブジェクトにしたものが サーブレットです。サーブレットは WEBrick::HTTPServlet::AbstractServlet の サブクラスのインスタンスとして実装されます。
WEBrick はセッション管理の機能を提供しません。
ソースコード入手
Webrick はRuby の標準ライブラリなので、Githubの ruby リポジトリから入手する。
git clone git@github.com:ruby/ruby.git
tags ファイルつくる
webrickはlib/下にある。そこでctagsコマンドを実行する。
cd ruby/lib/webrick ctags -R
参考:ctagsと連携するように環境を構築する - Qiita
ファイル構成を見る
MacBook-Pro:webrick gaaamii$ tree . . ├── accesslog.rb ├── cgi.rb ├── compat.rb ├── config.rb ├── cookie.rb ├── htmlutils.rb ├── httpauth │ ├── authenticator.rb │ ├── basicauth.rb │ ├── digestauth.rb │ ├── htdigest.rb │ ├── htgroup.rb │ ├── htpasswd.rb │ └── userdb.rb ├── httpauth.rb ├── httpproxy.rb ├── httprequest.rb ├── httpresponse.rb ├── https.rb ├── httpserver.rb ├── httpservlet │ ├── abstract.rb │ ├── cgi_runner.rb │ ├── cgihandler.rb │ ├── erbhandler.rb │ ├── filehandler.rb │ └── prochandler.rb ├── httpservlet.rb ├── httpstatus.rb ├── httputils.rb ├── httpversion.rb ├── log.rb ├── server.rb ├── ssl.rb ├── tags ├── utils.rb └── version.rb
読むの開始
先ほどのワンライナーをふたたび見る。
WEBrick::HTTPServer.new(:DocumentRoot => "./", :Port => 8000).start
まずは以下からざっくりと追う。
- HTTPServer.new
- HTTPServer#start
HTTPServer.new
インスタンス初期化時に何をしているのか。mountというメソッドでパスにサーブレットを割り当てているようだ。あとは @virtual_hosts という配列を初期化している。
HTTPServer#start
HTTPServerのインスタンスメソッドstart見ようとしても、ない。継承元のGenericServerのものだとわかる。
GenericServer#start
さて、このstartメソッドは何をしてるのか。コメントがあるので、それを見る。
137 ## 138 # Starts the server and runs the +block+ for each connection. This method 139 # does not return until the server is stopped from a signal handler or 140 # another thread using #stop or #shutdown. 141 # 142 # If the block raises a subclass of StandardError the exception is logged 143 # and ignored. If an IOError or Errno::EBADF exception is raised the 144 # exception is ignored. If an Exception subclass is raised the exception 145 # is logged and re-raised which stops the server. 146 # 147 # To completely shut down a server call #shutdown from ensure: 148 # 149 # server = WEBrick::GenericServer.new 150 # # or WEBrick::HTTPServer.new 151 # 152 # begin 153 # server.start 154 # ensure 155 # server.shutdown 156 # end
意訳する。
「サーバーを起動してコネクション毎にブロックを実行する。このメソッドはシグナルハンドラあるいは他のスレッドの#stopか#shutdownによってサーバーが停止するまでreturnしない。(以降、例外捕捉の説明)」
スレッド <--(コネクション)--> クライアント スレッド <--(コネクション)--> クライアント スレッド <--(コネクション)--> クライアント
という感じで、スレッドとコネクションとクライアントが1対1対1の関係になるのがこのstartメソッドを見るとわかる。
この処理はbegin節で囲まれてた中で無限ループしていて、先のコメントにあったようにシグナルハンドラなんかによって停止されたときにこの節を抜ける。するとensure節が実行されて、サーバーが停止する。
というわけで、実際のコードの中身について、大事そうなものをかいつまんで見てみていく。
- server_type.start
server_type.start
server_type にはデフォルトではWEBrick::SimpleServerとなるので、このstartメソッドをみる。
(server.rb) 27 class SimpleServer 28 29 ## 30 # A SimpleServer only yields when you start it 31 32 def SimpleServer.start 33 yield 34 end 35 end
yieldの一行しかない。渡したブロックそのまま実行するということがわかる。
setup_shutdown_pipe
よくわからない。パイプってなんだ(あとでみる)
svrs = IO.select([sp, *@listeners], nil, nil, 2.0)
IO.selectが何をしているのか。Rubyの組み込みライブラリなので、まずドキュメントにあたった方がよさそうだ。
http://docs.ruby-lang.org/ja/2.2.0/class/IO.html
IOクラスとは、
基本的な入出力機能のためのクラスです。
とのこと。では、このselectというメソッドはなにか。
http://docs.ruby-lang.org/ja/2.2.0/class/IO.html#S_SELECT
与えられた入力/出力/例外待ちの IO オブジェクトの中から準備ができたものを それぞれ配列にして、配列の配列として返します。 タイムアウトした時には nil を返します。
ソースも見てみる。IOクラスはwebrickの中には見つからないので、今回は pry-doc というgemを使ってpry(対話環境)から場所を見つけることにする。
[1] pry(main)> show-source IO.select From: io.c (C Method): Owner: #<Class:IO> Visibility: public Number of lines: 22 static VALUE rb_f_select(int argc, VALUE *argv, VALUE obj)
Cのソースで、rb_f_selectという関数だということがわかった。
start_thread
ThreadGroup#add
ThreadGroup の定義元に飛びたいけど、これは組み込みライブラリ、つまりCのソースになるので、webrickの中にはいない。ということで、今回は pry-doc というgemを使ってpry(対話環境)上から場所を見つけることにする。
pry> show-source ThreadGroup#add
とすると、このメソッドの定義元がわかる。どうやらthread.c にある thgroup_addという関数らしい。
IO.select([sp, *@listeners], nil, nil, 2.0)
書き途中です。